|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
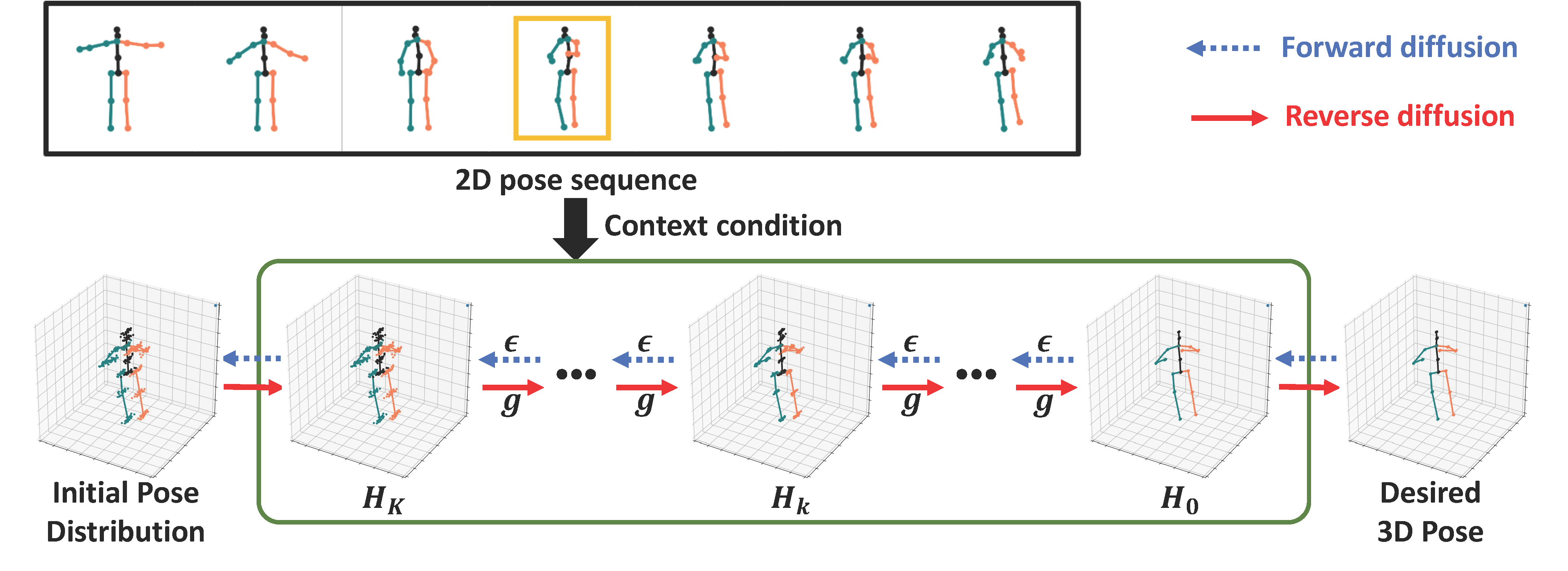
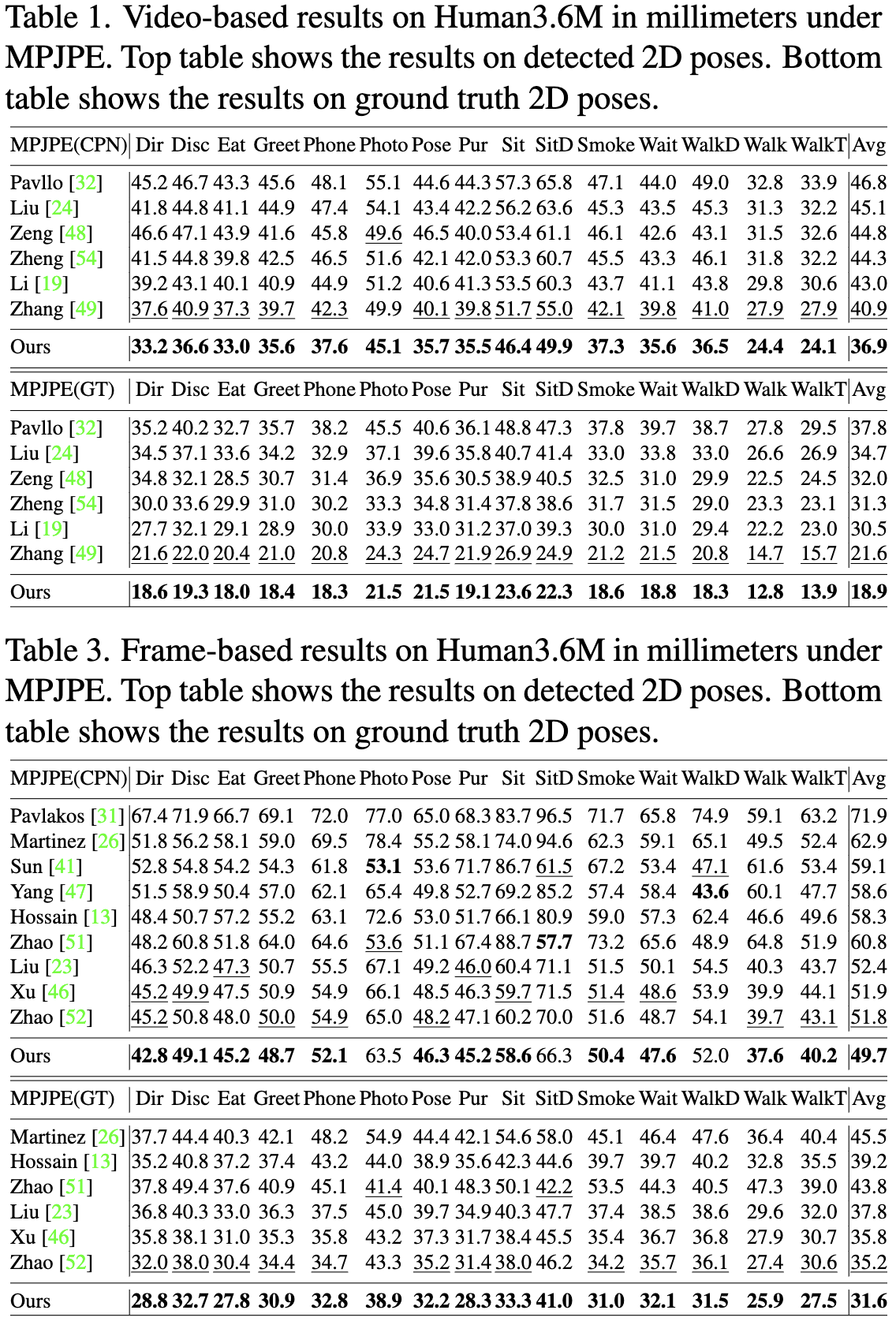
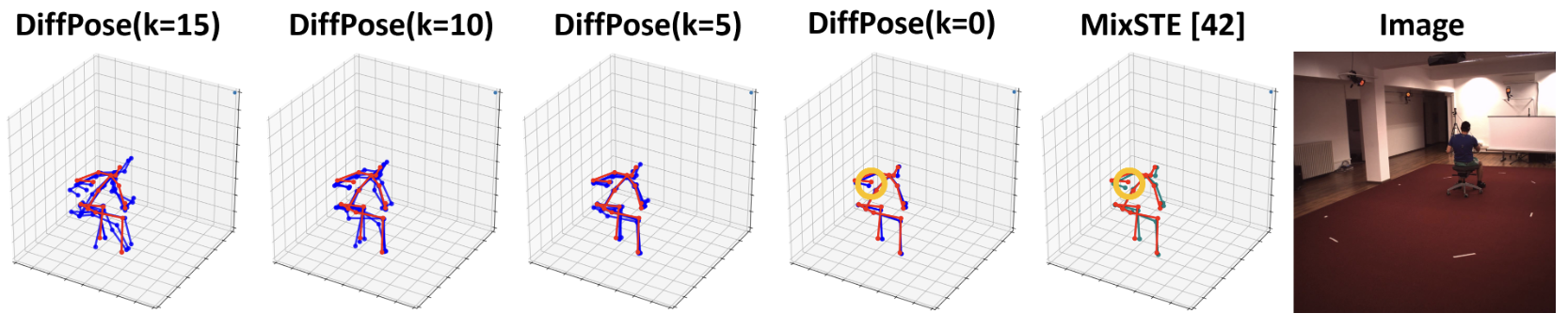
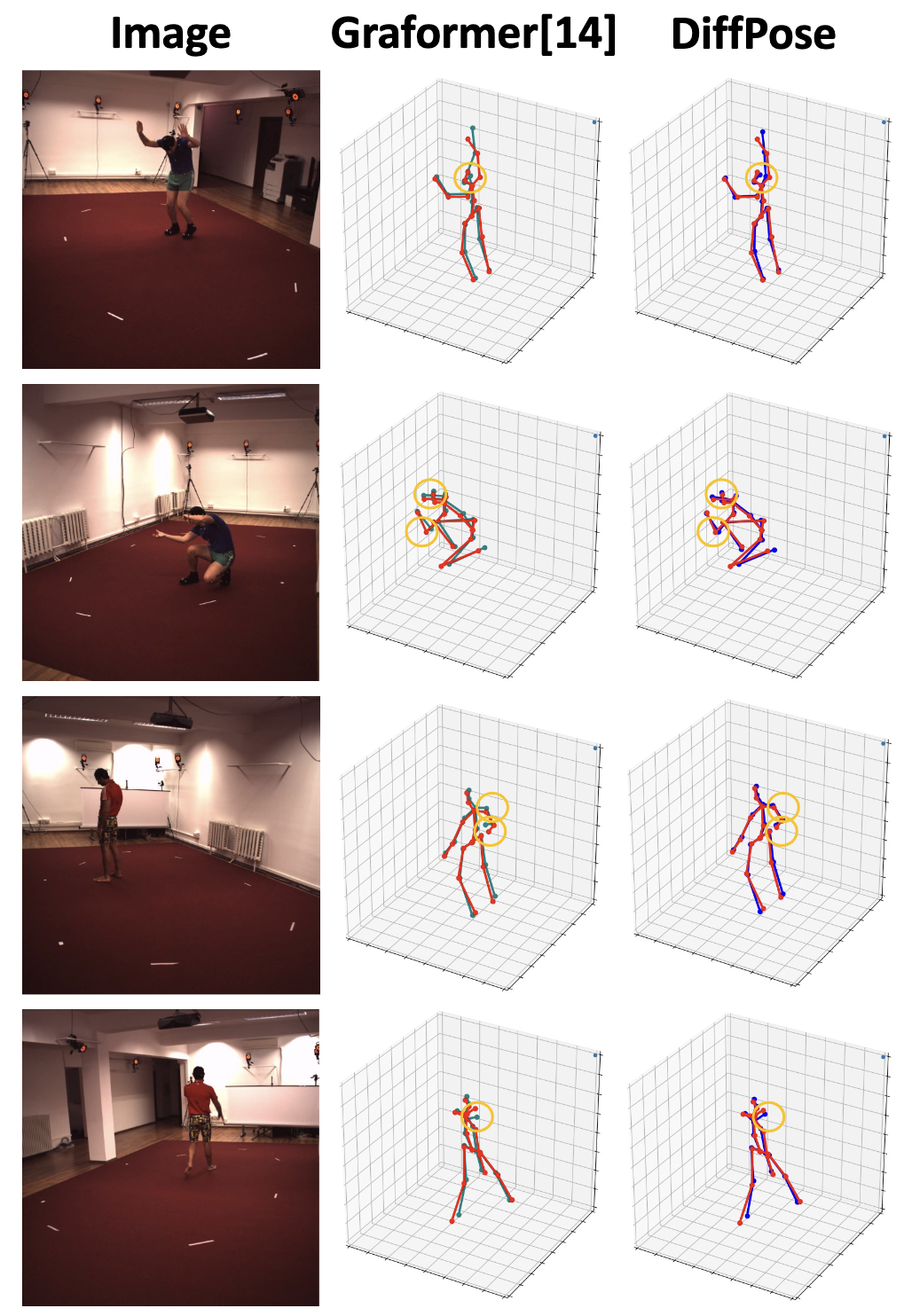
| Monocular 3D human pose estimation is quite challenging due to the inherent ambiguity and occlusion, which often lead to high uncertainty and indeterminacy. On the other hand, diffusion models have recently emerged as an effective tool for generating high-quality images from noise. Inspired by their capability, we explore a novel pose estimation framework (DiffPose) that formulates 3D pose estimation as a reverse diffusion process. We incorporate novel designs into our DiffPose that facilitate the diffusion process for 3D pose estimation: a pose-specific initialization of pose uncertainty distributions, a Gaussian Mixture Model-based forward diffusion process, and a context-conditioned reverse diffusion process. Our proposed DiffPose significantly outperforms existing methods on the widely used pose estimation benchmarks Human3.6M and MPI-INF-3DHP. |
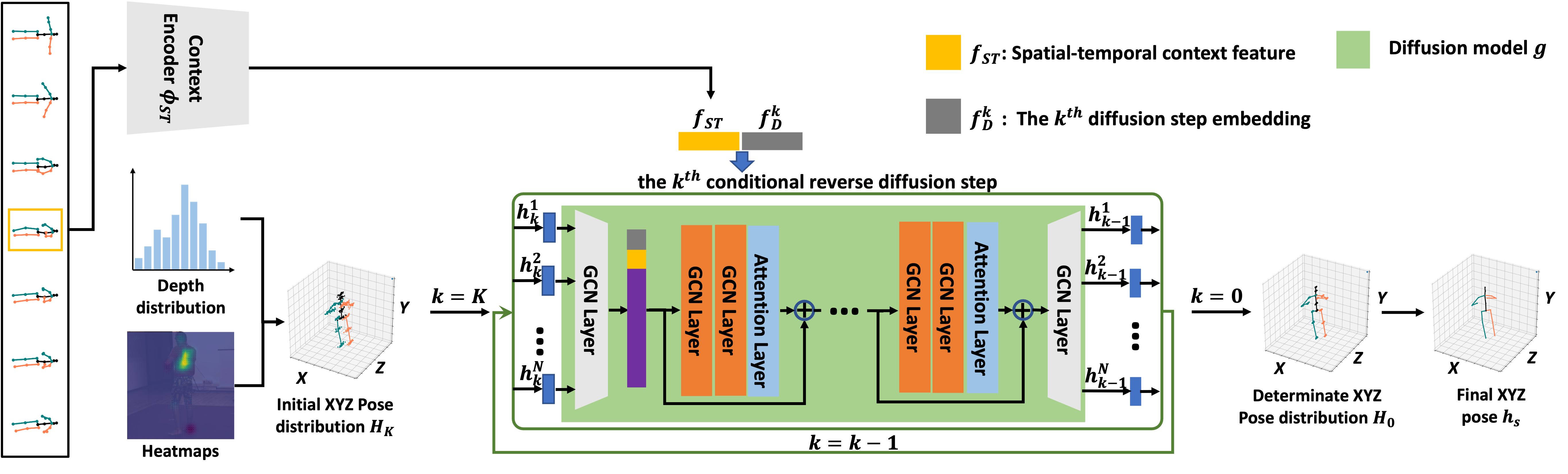 |
| Illustration of our DiffPose framework during inference. First, we use the Context Encoder \(\phi_{ST}\) to extract the spatial-temporal context feature \(f_{ST}\) from the given 2D pose sequence. We also generate diffusion step embedding \(f^k_D\) for each \(k^{th}\) diffusion step. Then, we initialize the indeterminate pose distribution $H_K$ using heatmaps derived from an off-the-shelf 2D pose detector and depth distributions computed from the training set or predicted by the Context Encoder \(\phi_{ST}\). Next, we sample $N$ noisy poses \(\{h^i_K\}_{i=1}^N\) from \(H_K\), which are required for performing distribution-to-distribution mapping. We feed these \(N\) poses into the diffusion model \(K\) times, where diffusion model $g$ is also conditioned on \(f_{ST}\) and \(f^k_D\) at each step, to obtain \(\{h^i_0\}_{i=1}^N\) which represents the high-quality determinate distribution \(H_0\). Lastly, we use the mean of \(\{h^i_0\}_{i=1}^N\) as our final 3D pose \(h_s\). |
 |
 |
 |
 |
Gong, J., Foo, L. G., Fan, Z., Ke, Q., Rahmani, H., & Liu, J. DiffPose: Toward More Reliable 3D Pose Estimation. In CVPR, 2023. (hosted on ArXiv) |
Acknowledgements |